






Применение современных компьютерных технологий в задачах анализа деятельности предприятий
Использование топ-менеджментом современных автоматизированных технологий управления данными и анализа информации, связанной с деятельностью предприятия, непрерывно возрастает. Руководитель привлекает на службу аналитиков, которые и помогают обеспечивать эффективное управление предприятием. В свою очередь, аналитики выполняют свою работу, используя системы поддержки принятия решений.
Будем рассматривать систему поддержки принятия решений (СППР, англ. Decision Support System, DSS) как компьютерную автоматизированную систему, цель которой – помощь аналитикам, принимающим решения в сложных условиях для полного и объективного анализа предметной деятельности.
К задачам СППР относятся:
- ввод данных – автоматически либо оператором;
- хранение данных – обеспечение надежности, предупреждение несанкционированного доступа, архивирование и др.;
- анализ данных – обеспечение аналитиков инструментарием для анализа данных.
В соответствии со своими задачами, СППР включает такие подсистемы (рис.1):
- подсистему ввода;
- подсистему хранения информации;
- подсистему анализа.
Ввод и хранение информации, а также задачи информационно-поисковых запросов эффективно реализуются средствами систем управления базами данных (СУБД), в которых реализована транзакционная обработка данных, т.е. OLTP-системами (англ. Online Transaction Processing).
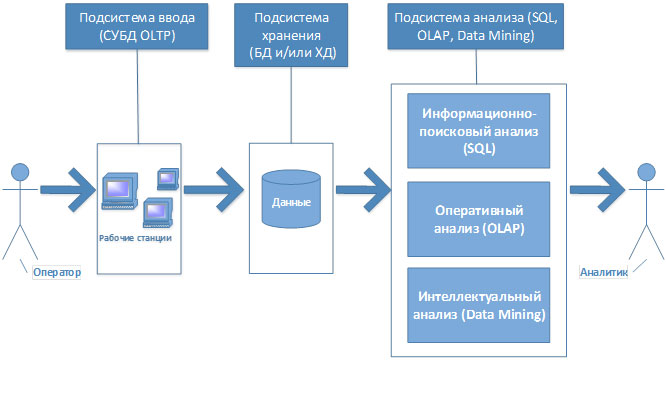
Рис.1 Предлагаемая структура СППР
Но для полноценного анализа данных, на основе которого строятся СППР, необходимо объединять информацию, хранимую в разных транзакционных базах данных. Более того, нередко бывает необходимо принимать во внимание информацию, хранящуюся в других, отличных от транзакционных баз данных, форматах. Представим себе корпорацию, состоящую из нескольких подразделений, возможно, территориально расположенных на достаточном расстоянии друг от друга. Для принятия решений по этой корпорации необходимо учитывать информационные потоки, связанные с каждым из подразделений. Основная проблема, которая возникает при этом, связана с несогласованностью таких данных, их противоречивостью, отсутствием единого логичного подхода к корпоративным данным.
Для решения этой проблемы в качестве систем хранения информации в СППР используются хранилища данных (ХД, англ. Data Warehouse). ХД – это предметно-ориентированный, интегрированный, редко меняющийся, поддерживающий хронологию, набор данных, организованный для целей поддержки принятия решений.
Подсистема анализа, в свою очередь, состоит из трех подсистем, связанных с разными подходами анализа данных.
Подсистема информационного-поискового анализа основана на использовании запросов, построенных на языке SQL (Structure Query Language). Эти запросы определяют алгоритм поиска информации как в транзакционных базах данных, так и в ХД. Однако, запросы на SQL ориентированы на достаточно небольшие объемы данных, поскольку время обработки запроса прямо пропорционально объему данных. СППР же требует анализа всей корпоративной информации, накапливаемой за достаточно большой отрезок времени, что приводит к необходимости обработки больших и очень больших объемов данных. Поэтому, как правило, подсистема информационного-поискового анализа может быть использована для небольших предприятий, для которых время для принятия решения не критично.
Подсистема оперативного анализа использует технологию OLAP (англ. Online Analytical Processing), т.е., технологию оперативной аналитической обработки данных, использующую методы и средства для сбора, хранения и анализа многомерных данных с целью поддержки процессов принятия решений. Хранилище данных и представляет собой многомерную структуру. Таким образом, OLAP-технология – эффективный инструментарий, дающий аналитику возможность принимать решения на основе анализа всей корпоративной информации за длительный промежуток времени.
Подсистема интеллектуального анализа построена на технологиях Data Mining. Григорий Пятецкий-Шапиро в 1996 году дал такое определение: «Data Mining – исследование и поиск “машиной” (алгоритмами, средствами искусственного интеллекта) в сырых данных спрятанных знаний, которые раньше не были известны, нетривиальные, практически полезные, доступные для интерпретации человеком». В буквальном переводе Data Mining – добыча золота. Возникновение такого термина связано с тем, что за последние десятилетия, благодаря интенсивному использованию баз данных на предприятиях, появился побочный продукт – горы собранной информации. И вот все больше распространяется идея, что эти горы полны золота. Возможно, в действии один из основополагающих философских законов – количество переходит в новое качество: критический объем информации может перейти в доселе неизвестные знания! Data Mining – это набор алгоритмов, позволяющих добыть новые знания из накопленной информации.
Статистические методы анализа данных и анализ данных с использованием OLAP-технологий в основном ориентированы на проверку заранее сформулированных гипотез. Инструменты Data Mining могут находить закономерности самостоятельно и также самостоятельно строить гипотезы.
Большинство статистических методов для обнаружения взаимосвязи между данными используют концепцию усреднения за выборкой, тогда как Data Mining оперирует реальными значениями.
OLAP используется для понимания ретроспективных данных, Data Mining опирается на ретроспективные данные для получения ответов на вопросы о будущем.
Задачи Data Mining тесно связаны с задачами, решаемыми в области теории распознавания образов:
- классификация;
- регрессия;
- поиск ассоциативных правил;
- кластеризация.
Основные стадии Data Mining определяются следующим образом:
- Свободный поиск – обнаружение закономерностей.
- Прогностическое моделирование – использование выявленных закономерностей для прогнозирования неизвестных значений.
- Анализ исключений – выявление и объяснение аномалий, найденных в закономерностях.
Упростит использование Data Mining специальное программное обеспечение. Поскольку Data Mining напрямую связано с накопленной информацией, соответствующее программное обеспечение – это дополнительные программные модули к СУБД. Так, например, в СУБД MS SQL Server может интегрироваться дополнительный программный модуль Business Intelligence Development Studio со службами SQL Server Analysis Services. Эти службы позволяют использовать целый ряд алгоритмов Data Mining. Первый из них – это алгоритм Microsoft Decision Trees (дерево решений), который представляет собой алгоритм классификации, использующийся для моделирования прогнозов и их анализа. Алгоритм выбирает самый вероятный результат для заданных входных данных из набора возможных результатов.
Чтобы определить, может ли построенная модель в виде дерева решений давать верный прогноз в будущем, и насколько точным он является, строится «Диаграмма точности прогнозов».
Алгоритм Microsoft Logistic Regression — это статистический регрессивный метод, использующийся в случае, когда прогнозируемая переменная может принимать только конечное множество значений.
Алгоритм поиска ассоциативных правил используется для определения ассоциаций либо зависимостей. Этот алгоритм полезен для механизмов формирования рекомендаций.
Технология Data Mining постоянно развивается, привлекая к себе все больший интерес, как со стороны научного мира, так и со стороны применения достижений технологий в бизнесе. Ежегодно проводится множество научных и практических конференций, посвященных Data Mining, одна из которых – Международная конференция «Knowledge Discovery Data Mining (International Conferences on Knowledge Discovery and Data Mining)». Среди наиболее известных WWW-источников — сайт www.kdnuggets.com, который ведет один из основателей Data Mining Григорий Пятецкий-Шапиро.
Использование описанных в статье информационных технологий в промышленном птичнике, содержащем около 30 000 кур-несушек, позволили определить параметры микроклимата, при которых не только достигается максимальная яйценоскость, но и возможно получение максимальной прибыли.
Также описанные технологии были использованы при введении племенного реестра животноводства. Это позволило усовершенствовать модель классификации хозяйств по направлениям их деятельности, разработать регрессионную модель, позволяющую прогнозировать надои молока по третьей лактации на основе данных по двум предыдущим лактациям, рассчитать ключевые показатели эффективности рентабельности племенных хозяйств.
Таким образом, топ-менеджмент благодаря современным компьютерным технологиям анализа накопленной информации получает возможность эффективного управления предприятием. Именно в информации, накопленной годами, а иногда и десятилетиями, кроется ответ на вопрос, по какому пути следует развивать деятельность предприятия.



{kind=link}